SILK: Smooth InterpoLation frameworK for motion in-betweening
Elly Akhoundi, SEED (Electronic Arts), Canada Hung Yu Ling, Electronic Arts, Canada Anup Anand Deshmukh, Electronic Arts, Canada Judith Bütepage, SEED (Electronic Arts), Sweden
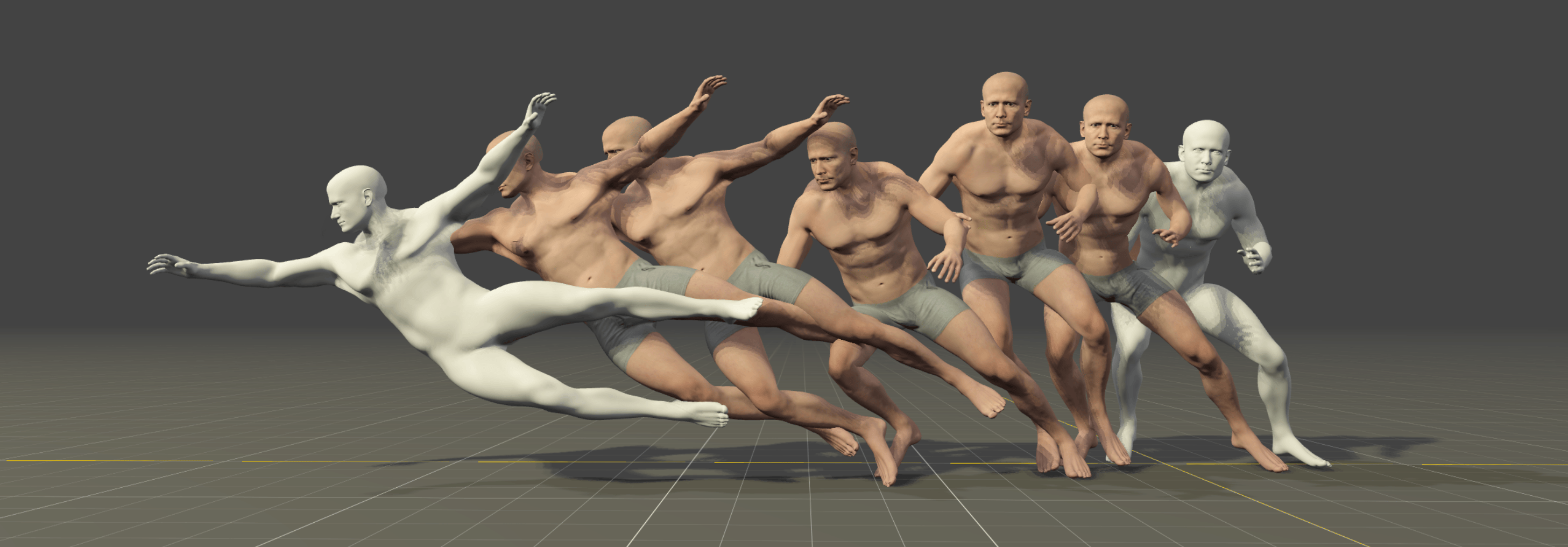
Paper: ArXiv / HuMoGen: Website
Motion in-betweening is a crucial tool for animators, enabling intricate control over pose-level details in each keyframe. Recent machine learning solutions for motion in-betweening rely on complex models, incorporating skeleton-aware architectures or requiring multiple modules and training steps. In this work, we introduce a simple yet effective Transformer-based framework, employing a single Transformer encoder to synthesize realistic motions for motion in-betweening tasks. We find that data modeling choices play a significant role in improving in-betweening performance. Among others, we show that increasing data volume can yield equivalent or improved motion transitions, that the choice of pose representation is vital for achieving high-quality results, and that incorporating velocity input features enhances animation performance. These findings challenge the assumption that model complexity is the primary determinant of animation quality and provide insights into a more data-centric approach to motion interpolation.
Summary
SILK achieves equal or better performance compared to state-of-the-art models by eliminating unnecessary architectural complexity. We show that using an appropriate pose representation and including velocity features improves performance. Crucially, our experiments identify the data sampling strategy as the key enabler for training simple models like SILK.
Internal Soccer Motion Results
We train SILK on a larger and noisier dataset. The goal is to evaluate its capabilities when trained on motion capture data that better reflects average quality. The dataset contains around 40 hours of mixed quality soccer movements. Videos below show SILK's predictions on some of the held-out testing motion sequences.
The videos are shown at half speed (50%) by default.
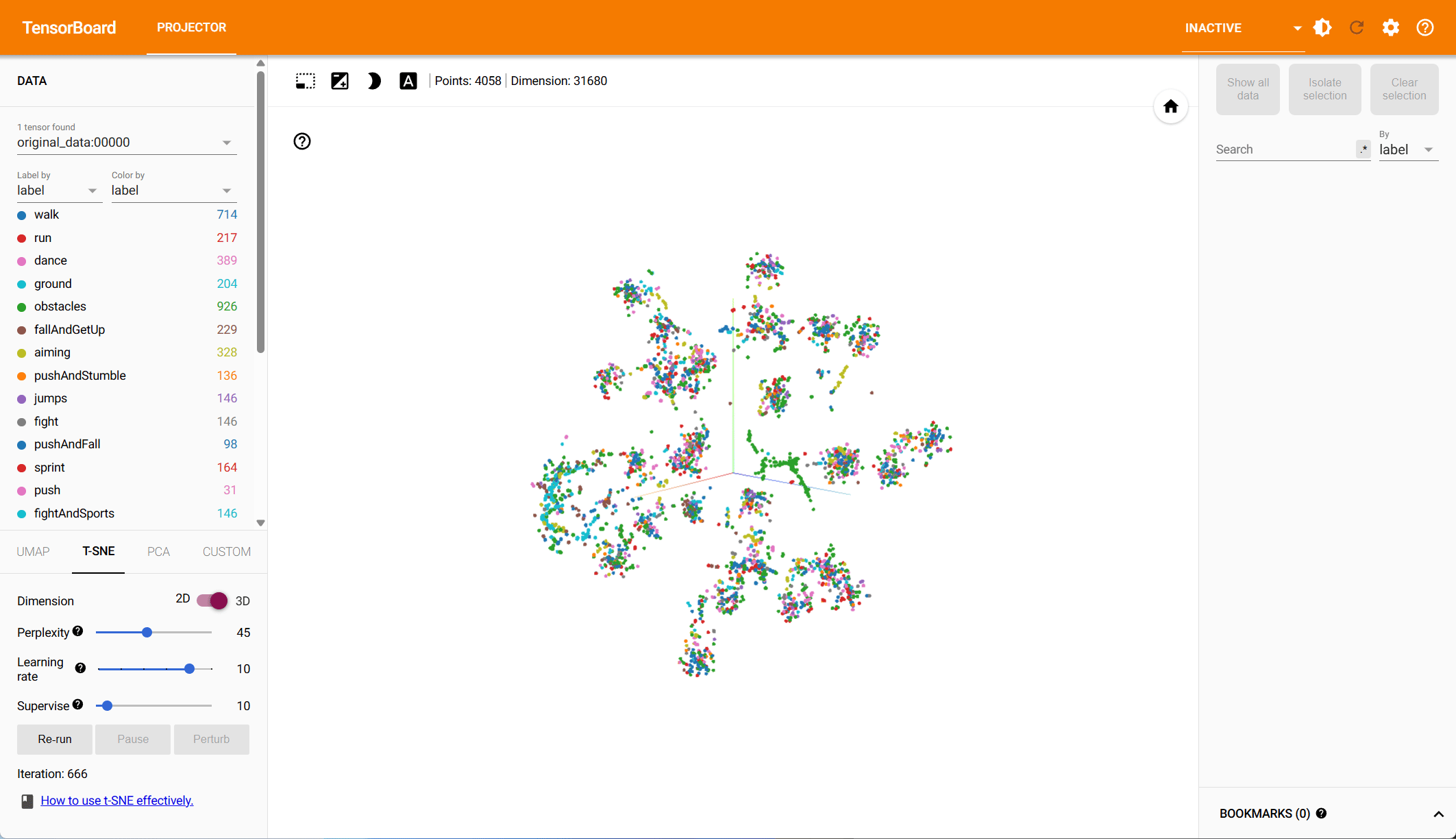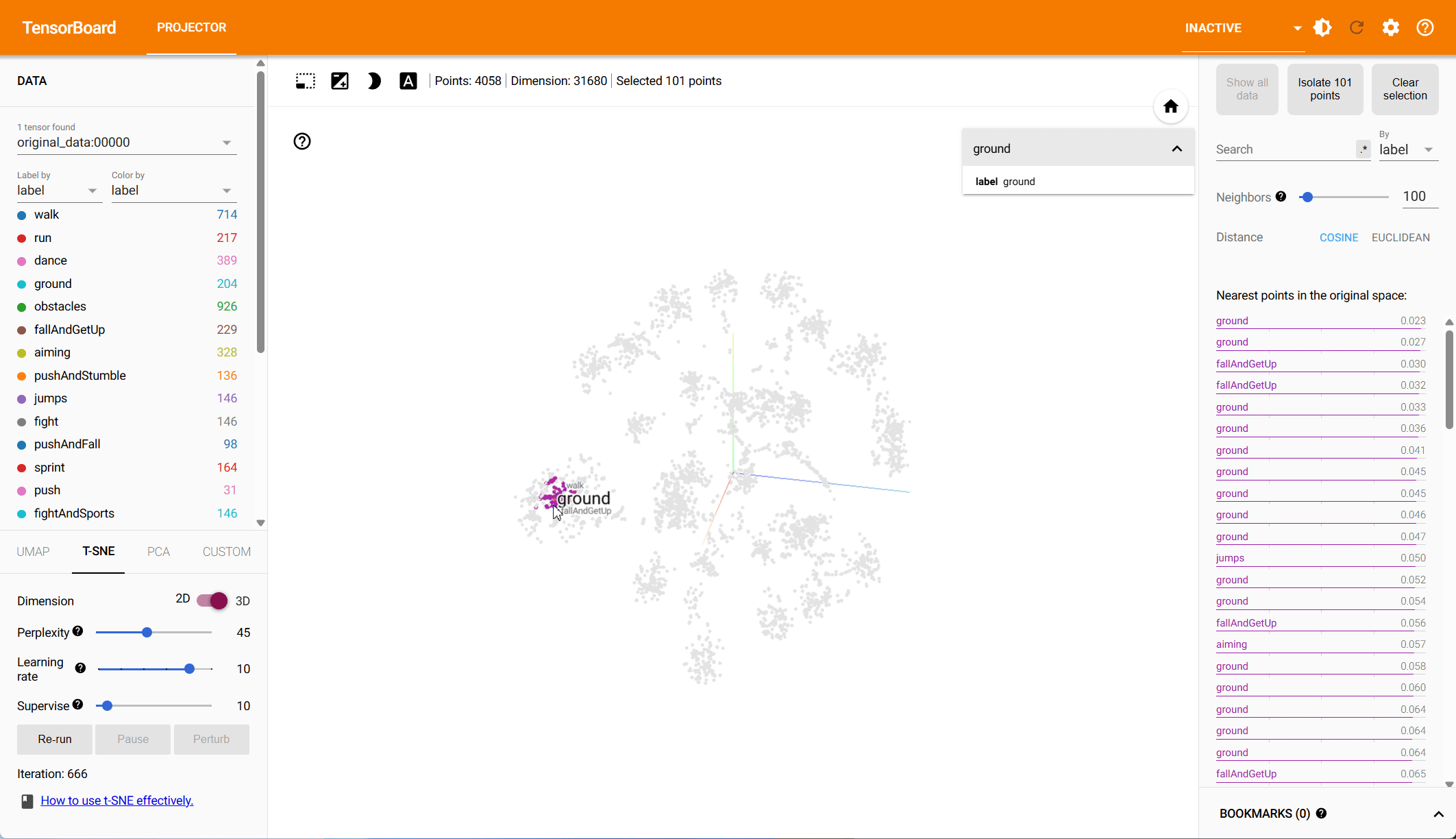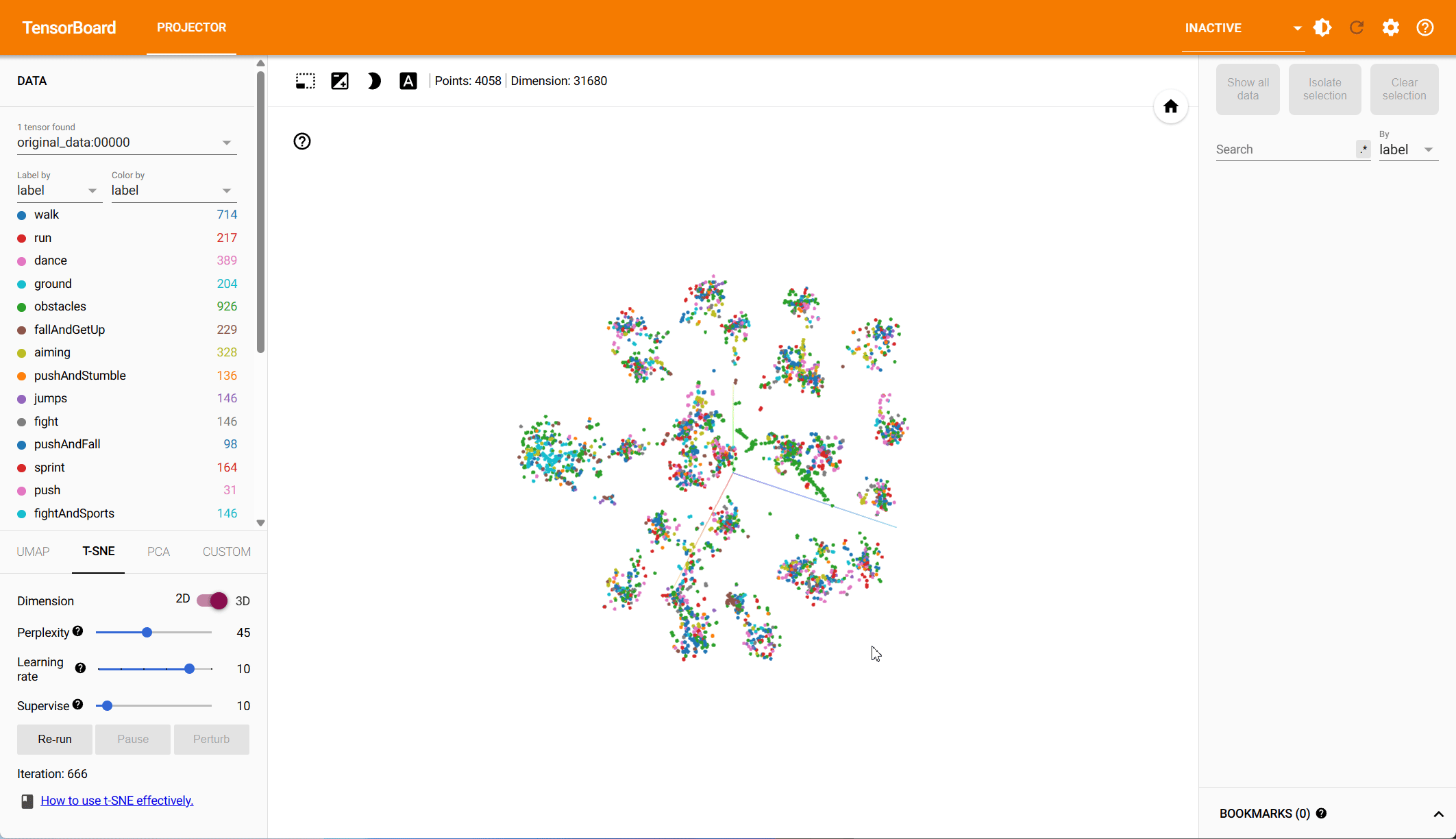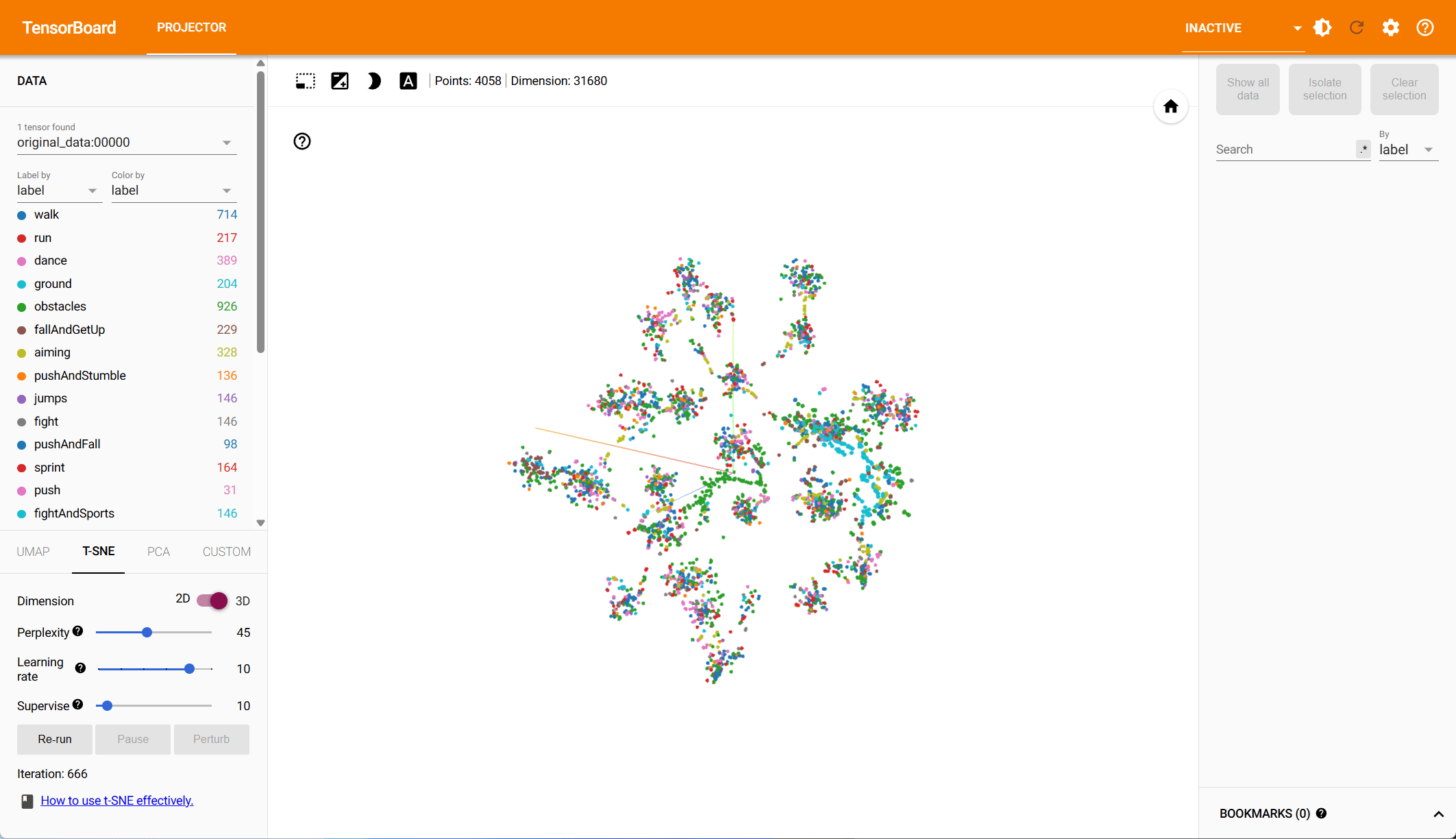
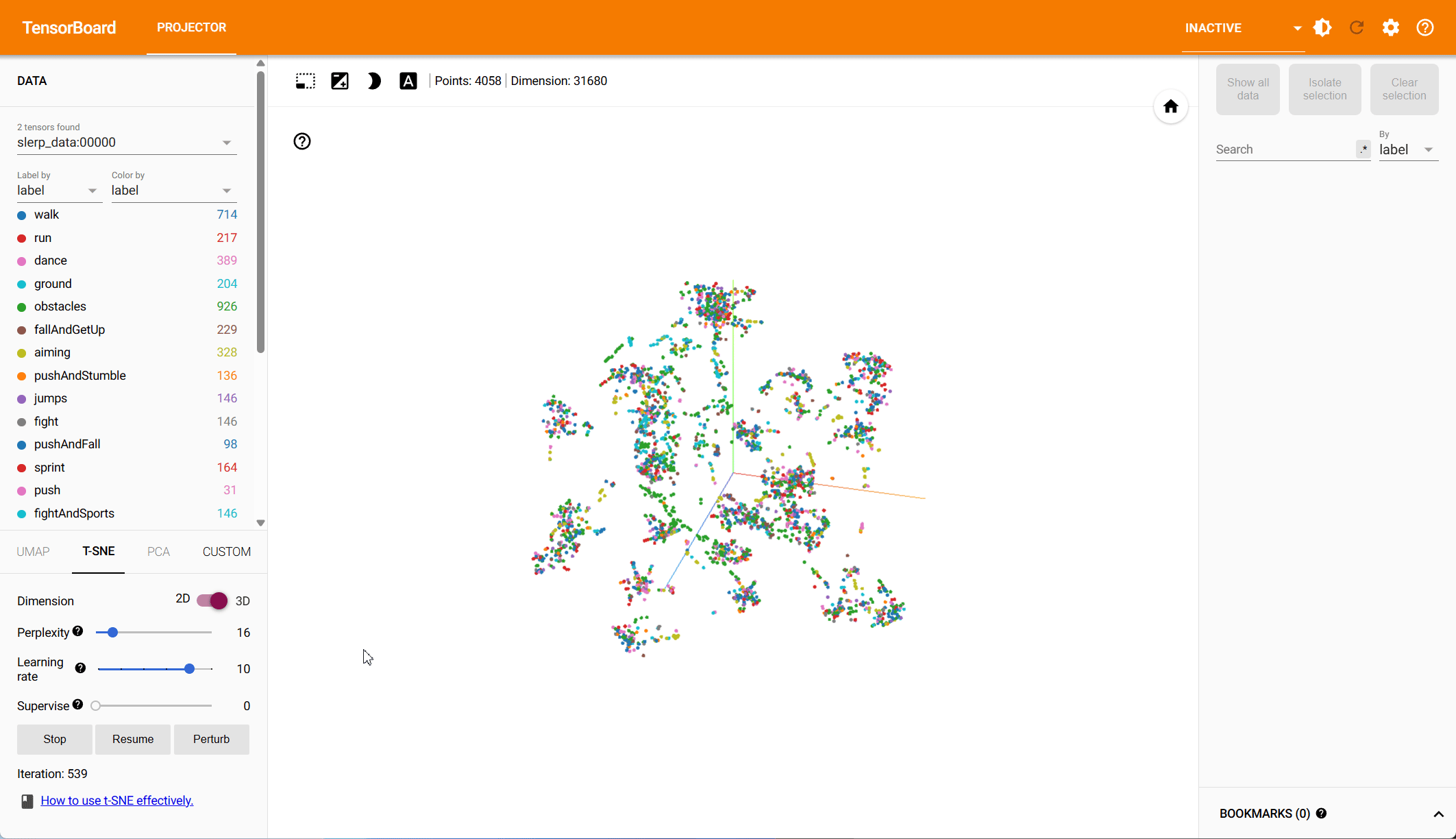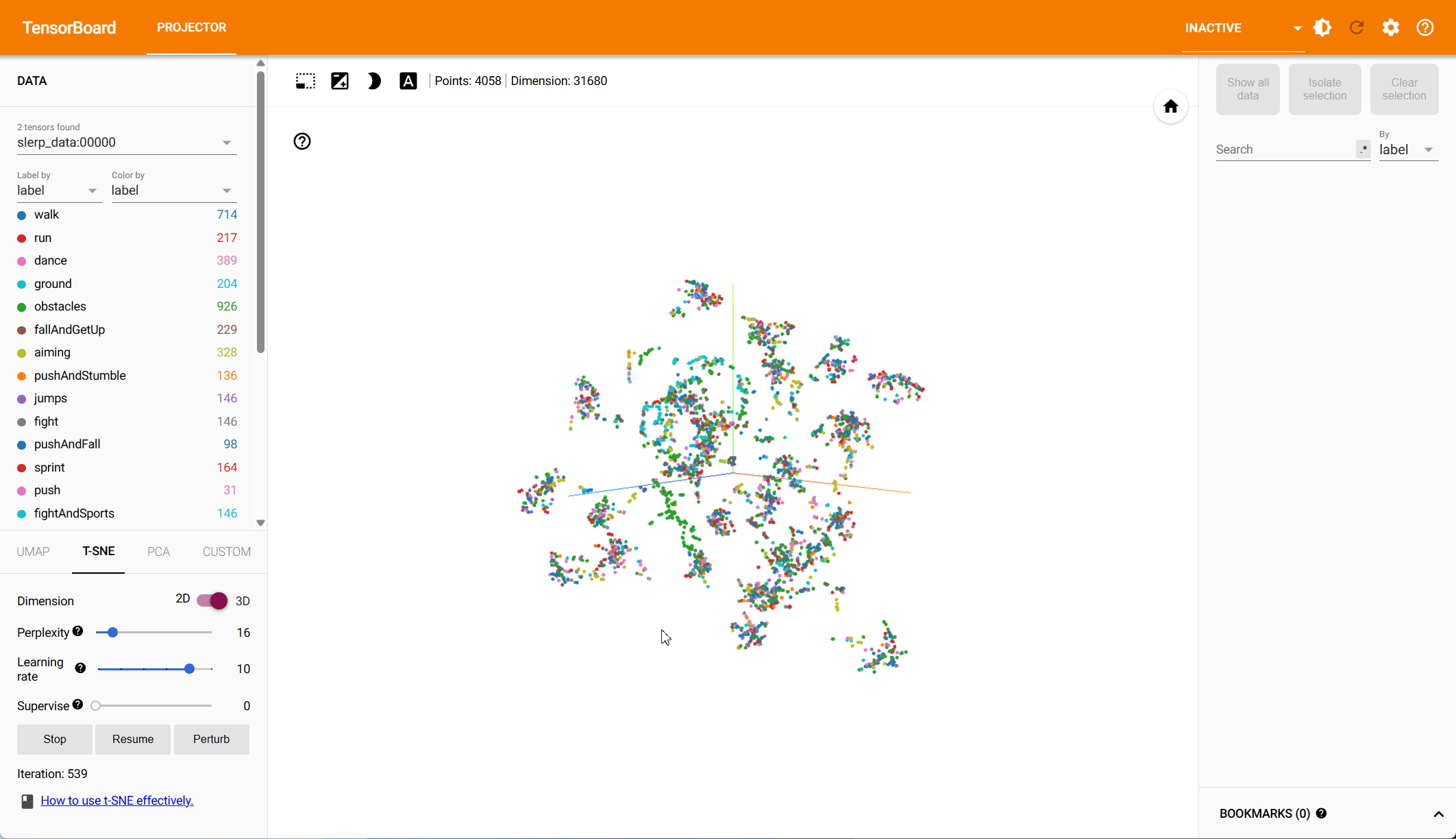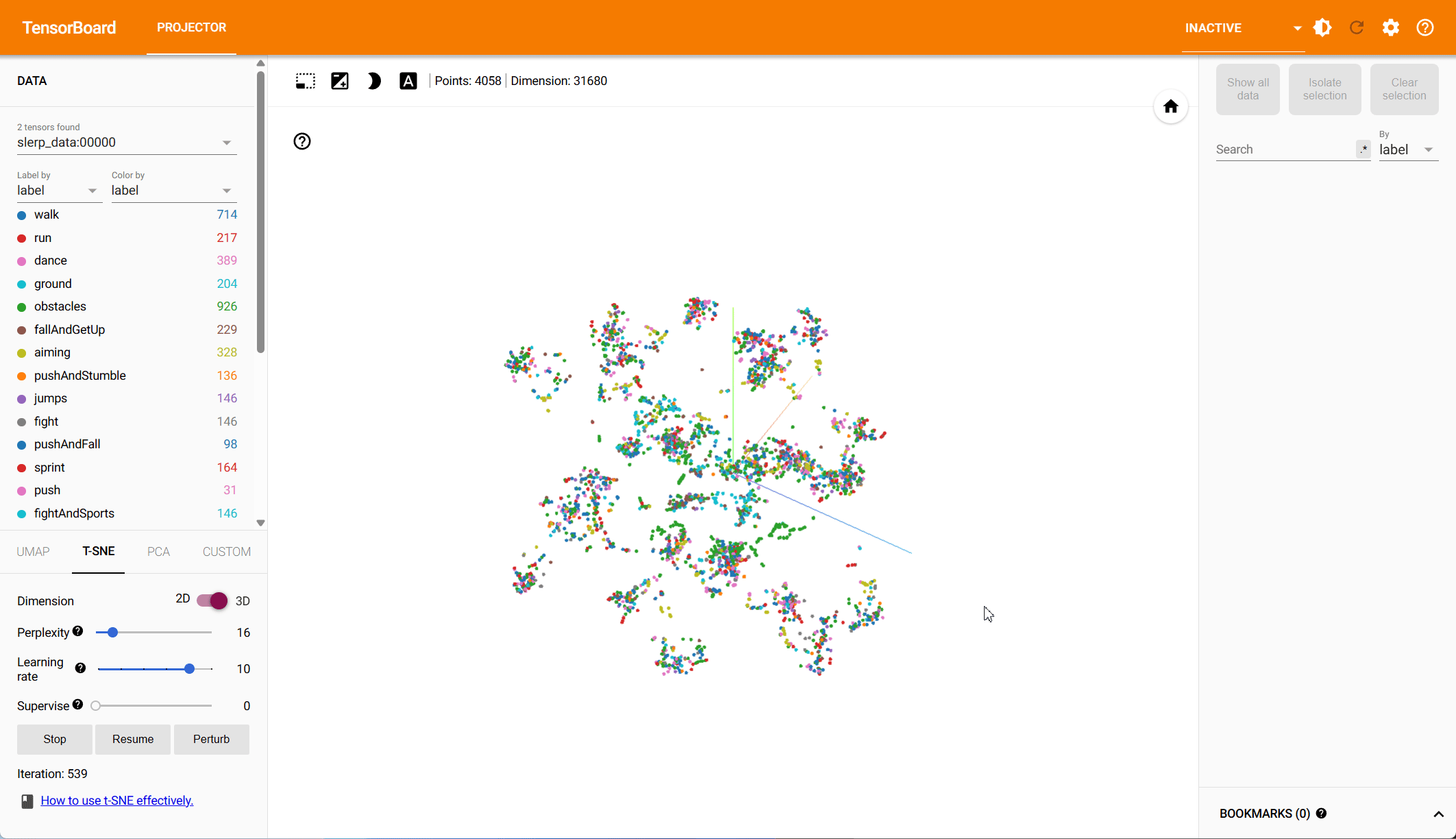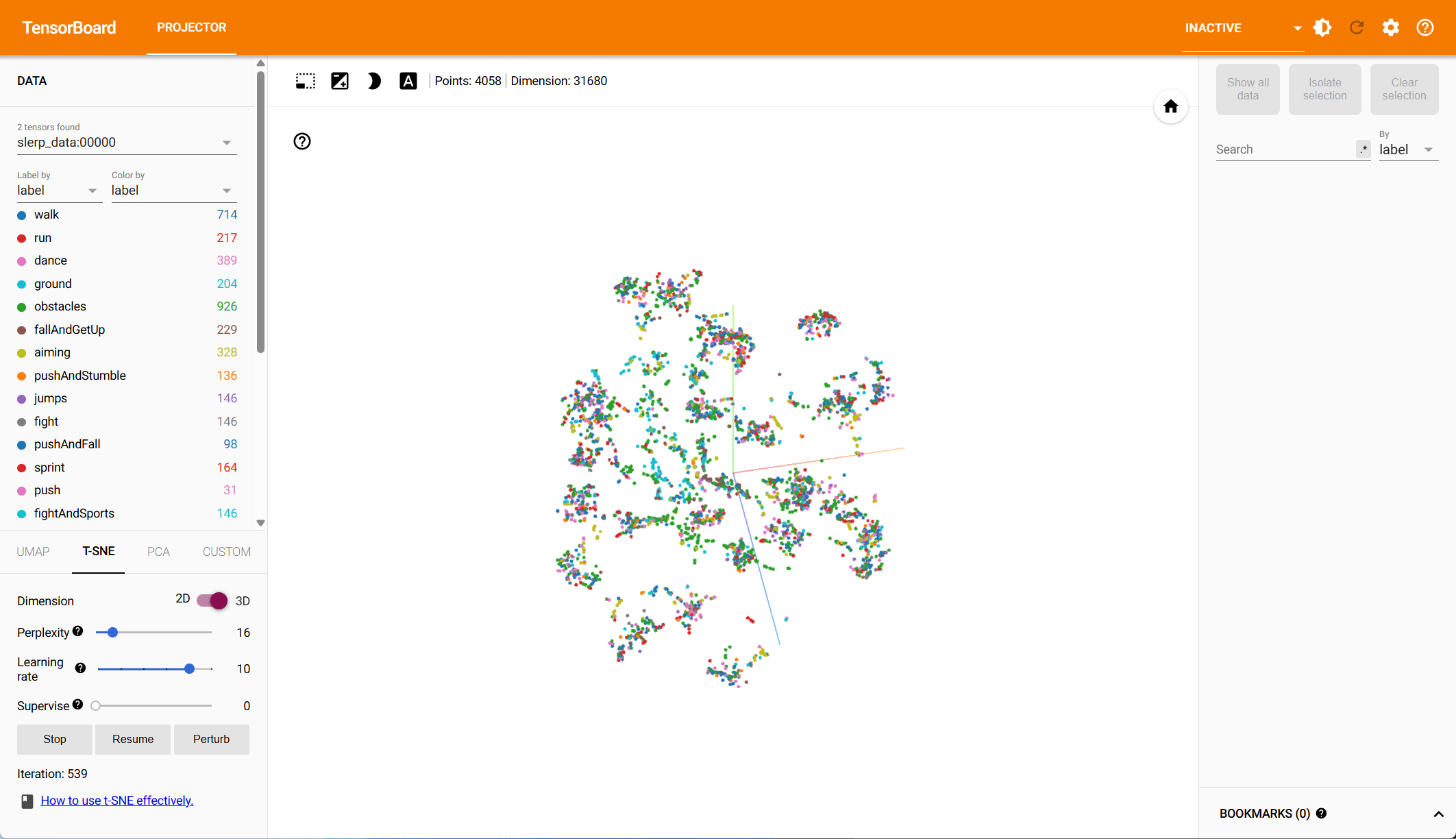
Pose Representation Comparison – t-SNE Visualization
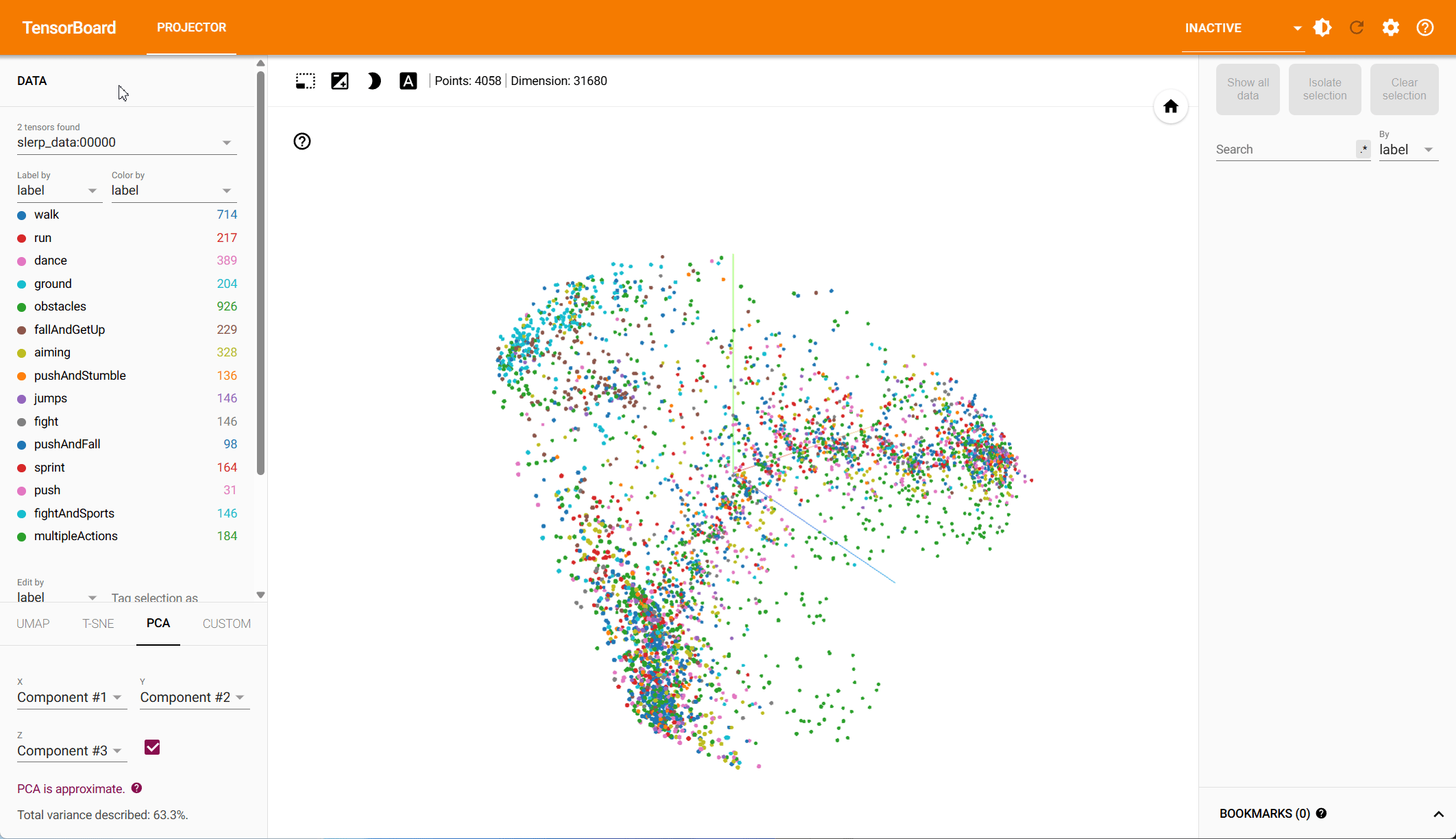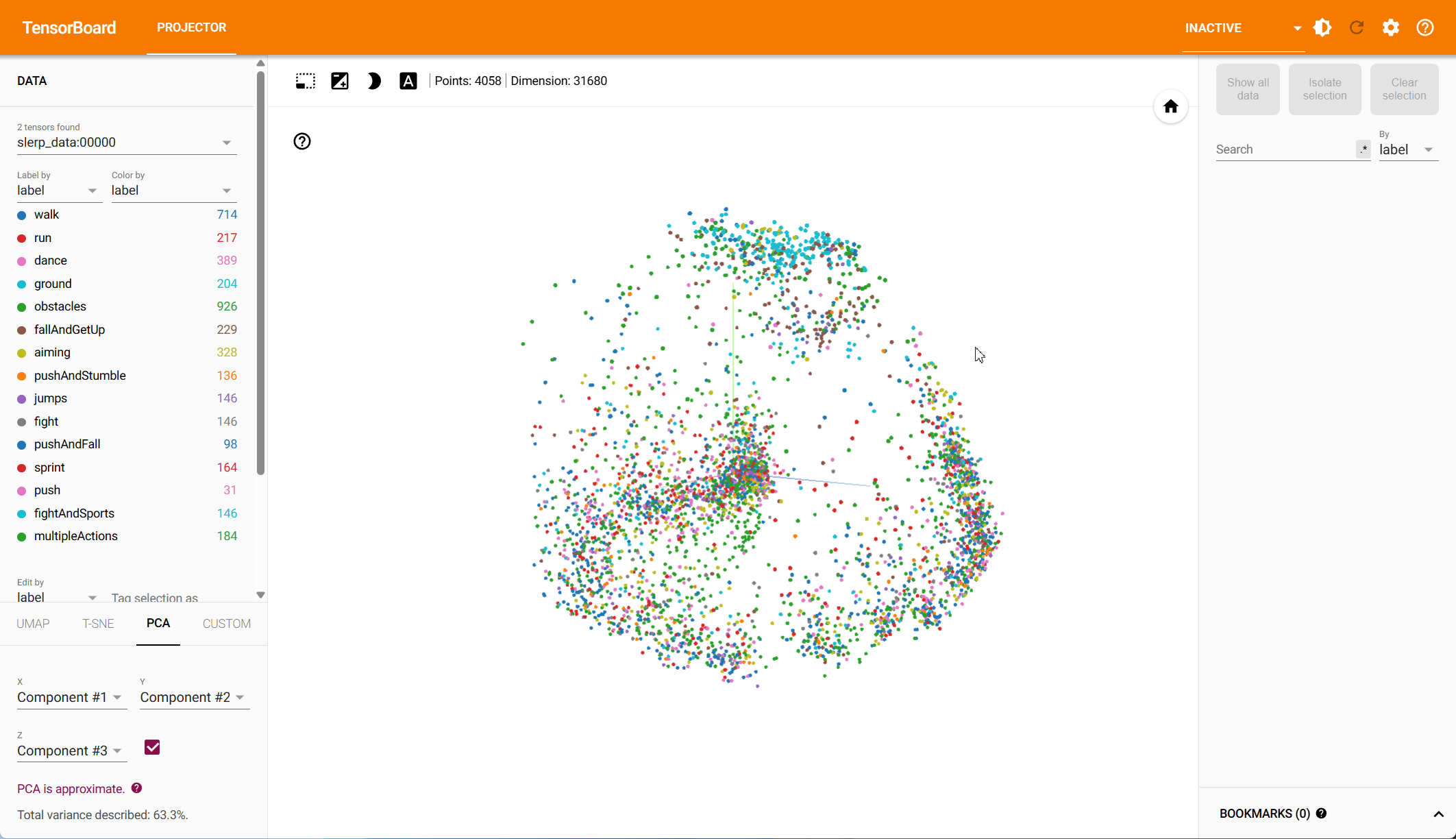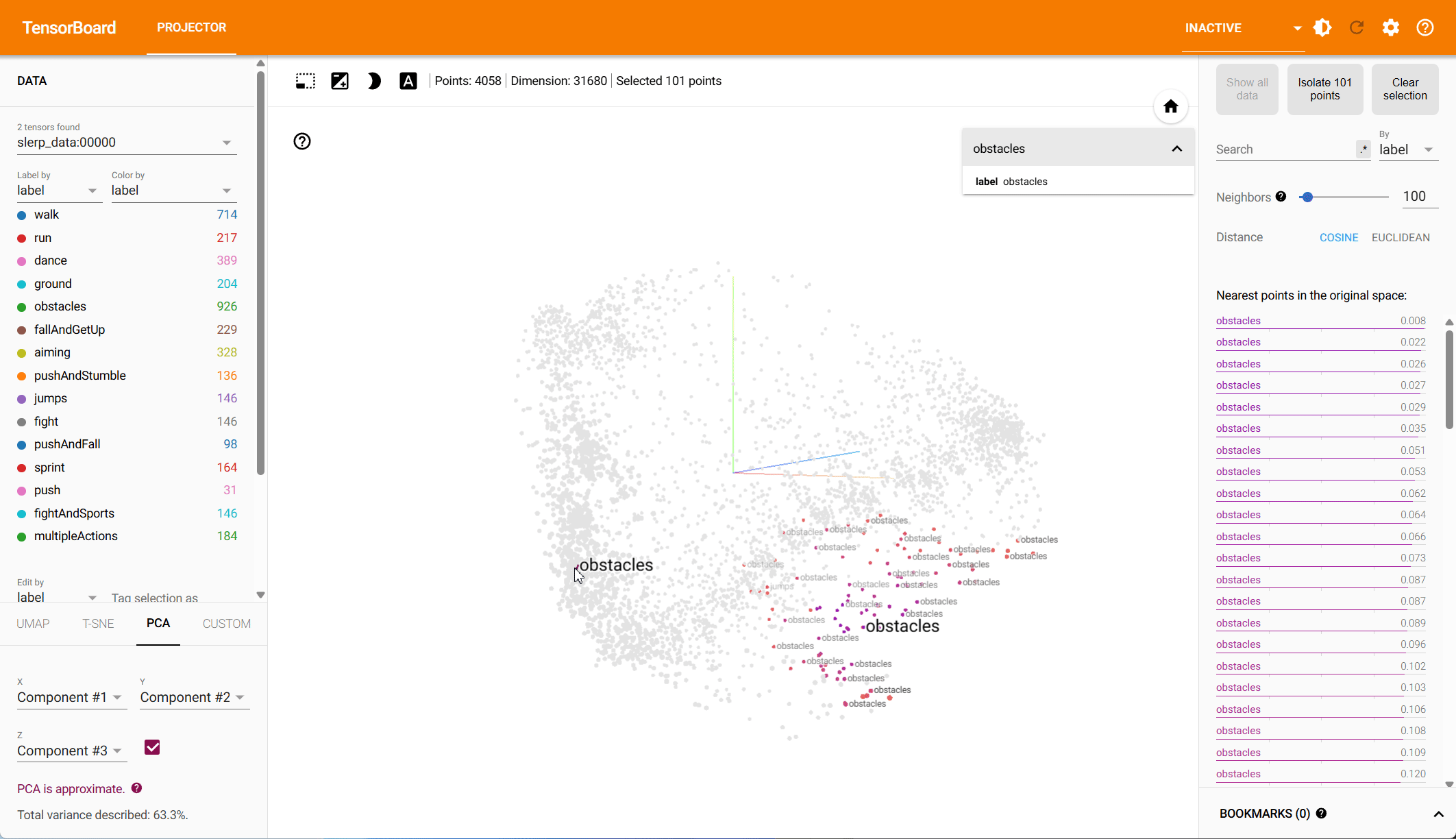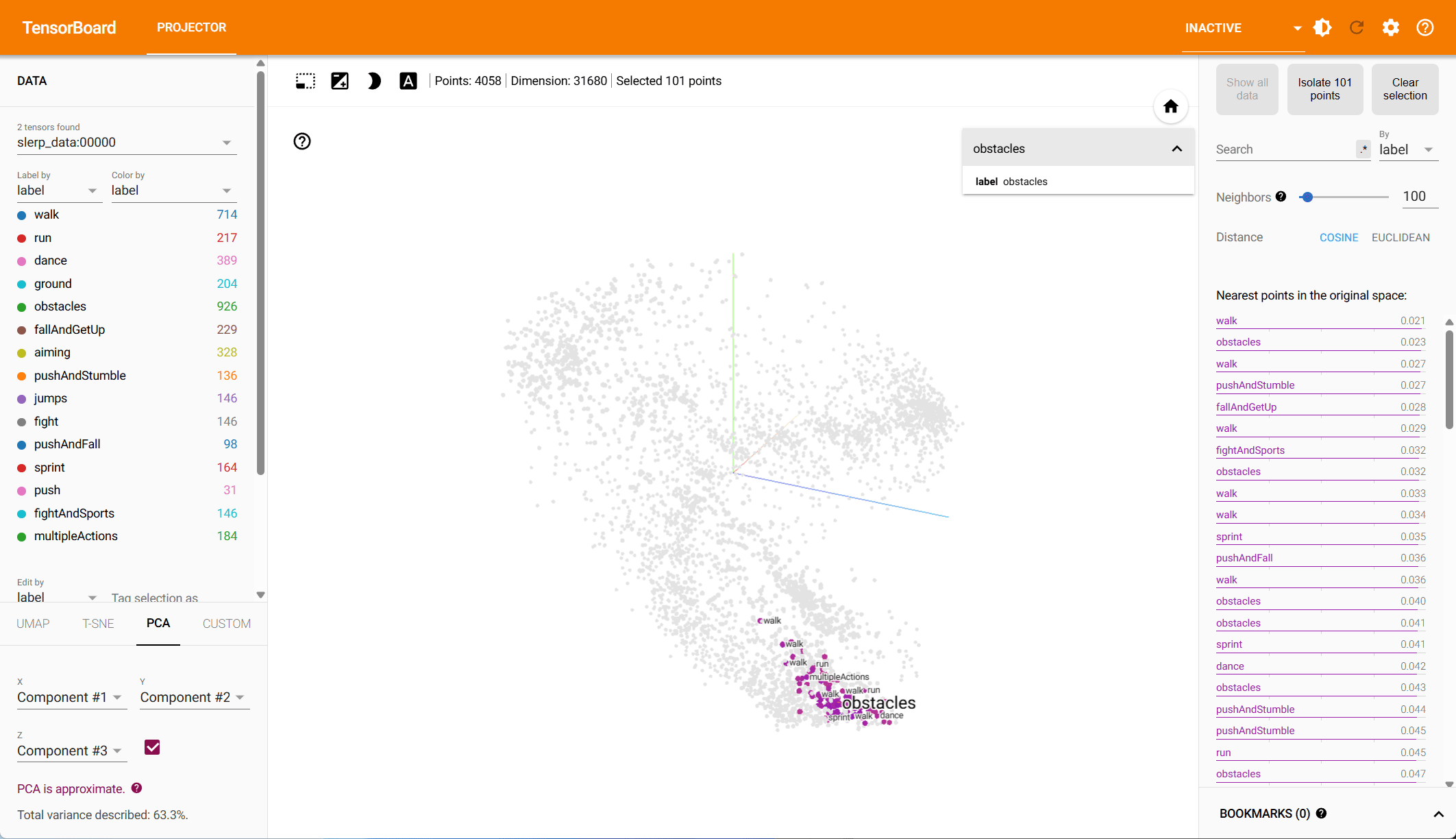
Based on both PCA and t-SNE plots, we see more distinct clusters in the data within the root-space, each associated with different animation types. Some action types have natural overlap, e.g., walking and running motions exist in other action classes, while others should be clearly distinct. Our hypothesis is that the more structured the data is in the reduced dimension, the easier it is for the model to make predictions.
To quantify the clustering, we cluster the data in both the PCA and the t-SNE space using k-means and compute the v-score. The v-score assesses completeness and homogeneity of clusters with respect to the provided ground truth labels. For PCA, on root and local features, we find a v-score of 0.2317 and 0.191 respectively. For t-SNE, we record a v-score of 0.41 for root features and 0.32 for local features.
PCA – Local-to-Parent Space
PCA – Root Space
t-SNE – Local-to-Parent Space
t-SNE – Root Space